
![[教程]本地部署 AI作畫工具 stable-diffusion-webui 多種模型 可生成NSFW](https://image.tiangal.com/uploads/2022/11/2022111113235956.webp)
AI作畫最近非常火熱啊,本文是在使用N卡的電腦上,本地部署stable-diffusion-webui前端+替換預設的模型,實現生成高質量的二次元影像,並且可以不受限制的生成圖片(線上版一般會阻止NSFW內容生成)。
所需資源下載位置:
Git:https://git-scm.com/download
CUDA:https://developer.nvidia.com/cuda-toolkit-archive
Python3.10.6:https://www.python.org/downloads/release/python-3106/
waifu-diffusion:https://huggingface.co/hakurei/waifu-diffusion
waifu-diffusion-v1-3:https://huggingface.co/hakurei/waifu-diffusion-v1-3
stable-diffusion-v-1-4-original: https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
stable-diffusion-v-1-5: https://huggingface.co/runwayml/stable-diffusion-v1-5
stable-diffusion-webui:https://github.com/AUTOMATIC1111/stable-diffusion-webui
NovelAILeaks 4chan:https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/naifu.tar
NovelAILeaks animefull-latest:https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/animefull-latest.tar
介紹
我們一起看下現在 AI 的作畫水平。
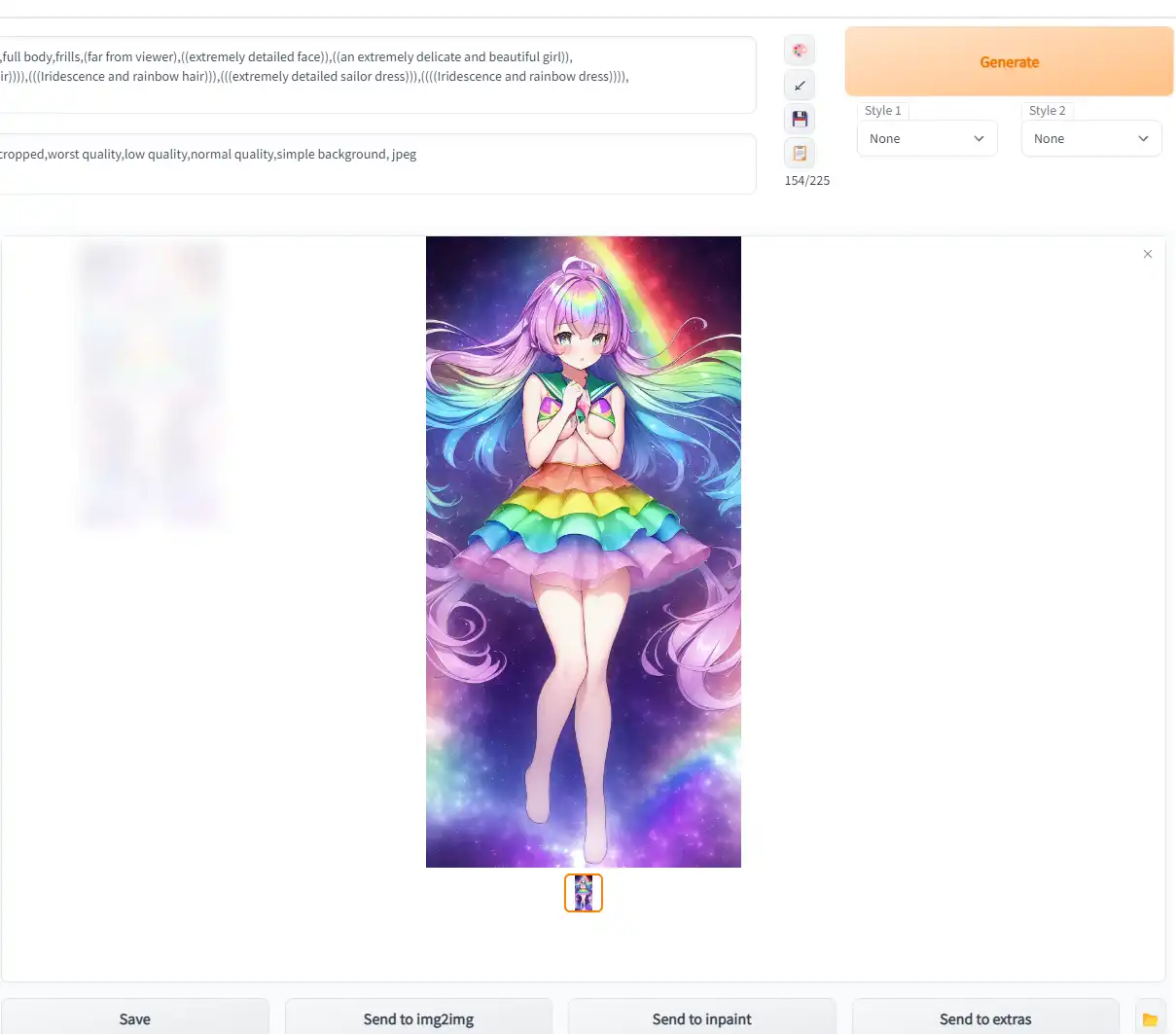
輸入文字關鍵詞描述,AI 直接生成影像作品:

輸入真實場景圖片,圖片二次元化:

甚至可以把自己二次元化:

這種演算法,不是檢索,檢索網路上已有的作品,而完全地重新創作。
開始
首先請確定你有基本的理解能力和動手能力,基本的網路搜尋檢索資訊的能力。過於基礎的東西比如“什麼是命令列”,“如何下載檔案”,“magnet是什麼東西”,“滿屏英語看不懂”,“怎麼給Python,Git加上魔法上網”等等這些過於基礎的問題,我這裡無法做出說明,也不會解答。
要順利執行 stable-diffusion-webui與模型,
需要足夠大的視訊記憶體,最低配置4GB視訊記憶體,基本配置6GB視訊記憶體,推薦配置12GB視訊記憶體。
當然記憶體也不能太小,最好大於16GB。
視訊記憶體大小決定了你能生成的圖片尺寸,一般而言圖片尺寸越大,AI能發揮的地方越多,畫面裡填充的細節就越多。
GPU主頻和視訊記憶體位寬,則決定了你能生成的多快。
當視訊記憶體不足時,只能用時間換效能,將生成時間延長4倍,甚至8~10倍來生成同樣的圖片。
教程部署環境為
CPU:Intel® Core™ i7-10750H
GPU:NVIDIA Quadro T2000 with Max-Q Design (視訊記憶體4GB)
記憶體:16GB * 4
磁碟:1TB * 2 SSD
OS:win11 21H1
準備執行環境
需要準備3個或4個東西
Python 3.10.6,Git ,CUDA,這三個的下載地址在文章的最前邊。
視情況,你可能還需要一個魔法上網工具(假設你的魔法上網工具代理在127.0.0.1:6808)
安裝 Python 3.10.6 與 pip
我這裡採用直接系統內安裝Python 3.10.6的方式
如果你會用Miniconda,也可以用Miniconda實現Python多版本切換,具體我這裡不教需要的自己琢磨。
訪問 Python3.10.6 下載頁面
把頁面拉到底,找到【Windows installer (64-bit)】點選下載
安裝是注意,到這一步,需要如下圖這樣勾選 Add Python to PATH
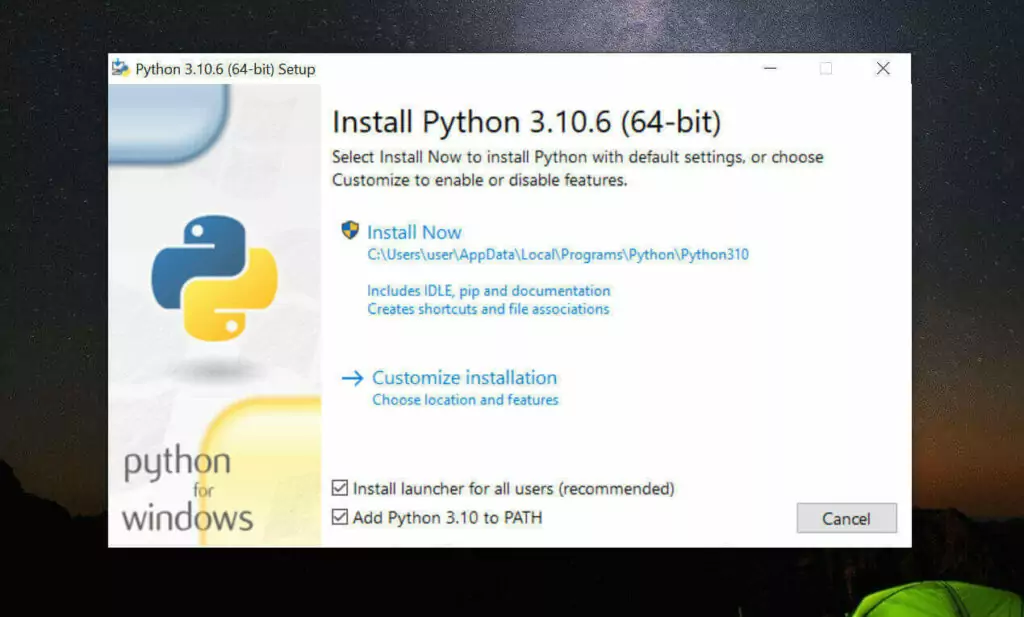
然後再點上邊的 Install Now
python
安裝完成後,命令列裡輸入Python -V,如果返回Python 3.10.6那就是成功安裝了。
命令列裡輸入 python -m pip install --upgrade pip安裝升級pip到最新版。
安裝 Git
訪問 Git 下載頁面
點選【Download for Windows】,【64-bit Git for Windows Setup】點選下載
一路下一步安裝
命令列執行git --version,返回git version 2.XX.0.windows.1就是安裝成功了。
安裝 CUDA
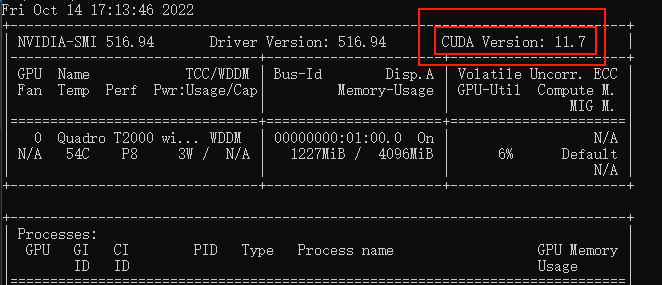
命令列執行nvidia-smi,看下自己顯示卡支援的 CUDA版本
(升級顯示卡驅動有可能會讓你支援更高版本的 CUDA)
接下來前往英偉達 CUDA 官網,下載對應版本。
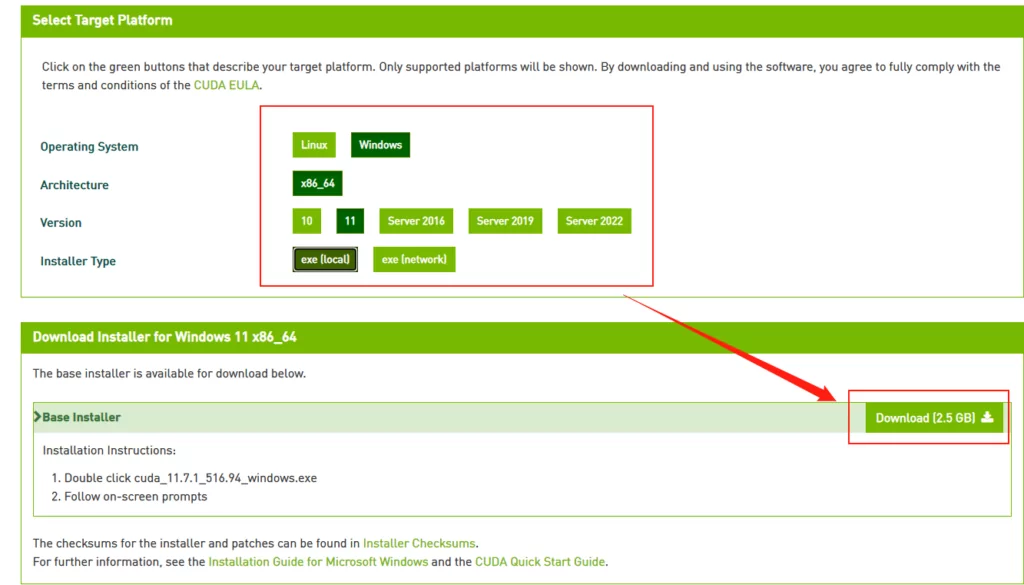
注意請下載,你對應的版本號最高的版本,比如我的是11.7的,那就下11.7.1(這裡最後的.1意思是,11.7版本的1號升級版)

選你自己的作業系統版本,注意下個離線安裝包【exe [local]】,線上安裝的話,速度還是比較堪憂的。
下載stable-diffusion-webui
找一個你喜歡的目錄,在資源管理器,位址列裡敲CMD,敲回車,啟動命令提示行視窗,輸入以下命令
# 下載專案原始碼git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git# 切換到專案根目錄cd stable-diffusion-webui
他會在你選擇的目錄下生成stable-diffusion-webui資料夾,放專案
這東西本體+虛擬環境+集中模型+增強指令碼最後會很大的,目前我已經佔用了快20GB了,請放到磁碟空間富裕的磁碟機代號
整個路徑中,不要有中文(比如“C:\AI作畫工具\”),也不要有空格(比如“C:\Program Files”)可以避免很多奇怪的問題。
下載模型檔案
stable-diffusion-webui只是個工具,他需要後端的訓練模型來讓AI參考建模。
目前比較主流的模型有
stable-diffusion:偏真人(一般簡稱為 SD 模型, SDwebui 模型)
waifu-diffusion:偏向二次元(一般簡稱 Waifu 模型,WD模型)
Novel-AI-Leaks:更加偏向二次元(一般簡稱 Naifu 模型)
模型檔案一般都比較大,請找個空間富裕的磁碟下載。
模型的大致區別
| 名稱 | 需求 | 效果 | 備註 |
|---|---|---|---|
| stable-diffusion (4GB emaonly模型) | 2GB 視訊記憶體起步 | 出圖速度 10s,單次最大出 920×920 | 適合出圖用 |
| stable-diffusion (7GB full ema模型) | 4GB 視訊記憶體起步 | 帶最後一次訓練的權重,所以費視訊記憶體 | 適合訓練用 |
| waifu (Float 16 EMA 模型) | 2GB視訊記憶體起步 | 與stable效能接近 ,視訊記憶體佔用略高 | 適合出圖用 |
| waifu (Float 32 EMA 模型) | 2GB視訊記憶體起步 | 與stable效能接近,視訊記憶體佔用略高 | 適合出圖用,出圖質量其實和16差別不大 |
| waifu (Float 32 Full 模型) | 4GB視訊記憶體起步 | 與stable效能接近,視訊記憶體佔用略高 | 適合出圖或訓練用 |
| waifu (Float 32 Full + Optimizer 模型) | 8GB視訊記憶體起步 | 與stable效能接近,視訊記憶體佔用略高 | 適合訓練用 |
| Naifu (4GB pruned 模型) | 最低8GB視訊記憶體&8GB視訊記憶體 | 和官方比較接近 | 適合出圖用 |
| Naifu (7GB latest模型) | 最低8GB視訊記憶體(向上浮動10GB) | 和官方比較接近 | 適合出圖或訓練用 |
注意這裡視訊記憶體指的是512X512尺寸,預設配置下,出圖時軟體所需要佔用的視訊記憶體。2GB視訊記憶體起步,意味浙你電腦顯示卡實際視訊記憶體最少也要3GB(因為系統桌面,瀏覽器的顯示也需要佔用一部分視訊記憶體)
透過增加各種“最佳化”引數,可以透過效能的部分下降換取視訊記憶體佔用減少。
Nafu模型名稱說明1:animefull-final-pruned = full-latest = NAI 全量模型(包含NSFW)
Nafu模型名稱說明2:animesfw-latest = NAI 基線模型
下載stable-diffusion
下載的方式有 3 個
官網下載:https://huggingface.co/CompVis/stable-diffusion-v-1-4-original
File storage:https://drive.yerf.org/wl/?id=EBfTrmcCCUAGaQBXVIj5lJmEhjoP1tgl
磁力連結 magnet:?xt=urn:btih:3a4a612d75ed088ea542acac52f9f45987488d1c&dn=sd-v1-4.ckpt&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337
將解壓出.ckpt檔案放在\stable-diffusion-webui\models\Stable-diffusion\ 下
檔名可以是任何你喜歡的英文名。比如stable-diffusion .ckpt
下載 waifu-diffusion
官網下載:https://huggingface.co/hakurei/waifu-diffusion-v1-3/tree/main
下那個 wd-v1-3-float16.ckpt 就行
將解壓出.ckpt檔案放在\stable-diffusion-webui\models\Stable-diffusion\ 下
檔名可以是任何你喜歡的英文名.比如waifu-diffusion-16.ckpt
下載 NovelAILeaks(推薦)
Naifu Leaks 4chan:https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/naifu.tar
Naifu Leaks animefull-latest:https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/animefull-latest.tar
找到naifu\models\animefull-final-pruned\model.ckpt放在\stable-diffusion-webui\models\Stable-diffusion\ 下檔名可以是任何你喜歡的英文名,比如Naifu-Leaks- 4chan.ckpt
找到naifu\models\animefull-final-pruned\config.yaml放在\stable-diffusion-webui\models\Stable-diffusion\ 下檔名改成上邊和你上邊的檔案同名,比如Naifu-Leaks- 4chan.yaml
找到naifu\modules\,把裡面所有的.pt檔案複製到\stable-diffusion-webui\models\hypernetworks\資料夾下,沒有這個資料夾就自己新建一個。
執行
雙擊執行\stable-diffusion-webui\webui-user.bat
耐心等待,指令碼會自己檢查依賴,會下載大約幾個G的東西,解壓安裝到資料夾內(視網速不同,可能需要20分鐘~2小時不等)無論看起來是不是半天沒變化,感覺像卡住了,或者你發現電腦也沒下載東西,視窗也沒變化。千萬不要關閉這個黑乎乎的CMD視窗,只要視窗最下方沒顯示類似“按任意鍵關閉視窗”的話,那指令碼就是依然在正常執行的。
當你看到下圖這行字的時候,就是安裝成功了
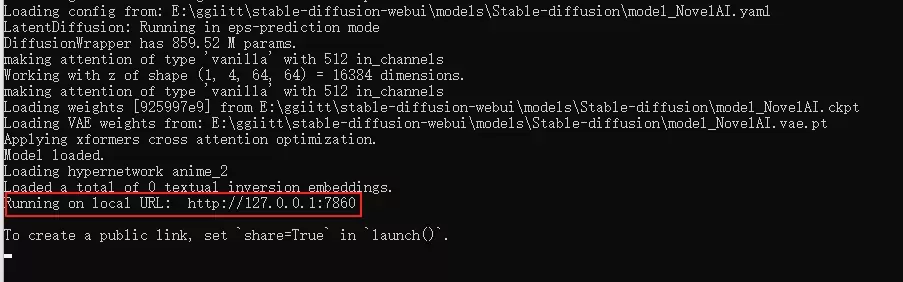
複製到瀏覽器訪問即可(預設是 http://127.0.0.1:7860 )(注意不要關閉這個視窗,關閉就退出了)
生成第一張AI作圖
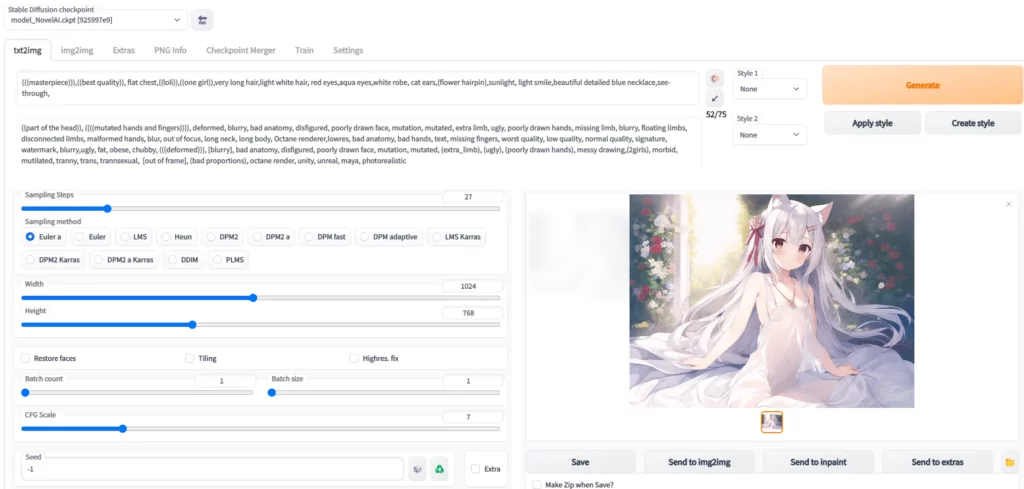
Prompt 裡填寫想要的特徵點
(((masterpiece))),((best quality)), flat chest,((loli)),((one girl)),very long light white hair, beautiful detailed red eyes,aqua eyes,white robe, cat ears,(flower hairpin),sunlight, light smile,blue necklace,see-through,
以上大概意思就是
傑作,最佳品質,貧乳,蘿莉,1個女孩,很長的頭髮,淡白色頭髮,紅色眼睛,淺綠色眼睛,白色長裙,貓耳,髮夾,陽光下,淡淡的微笑,藍色項鍊,透明
Negative prompt 裡填不想要的特徵點
((part of the head)), ((((mutated hands and fingers)))), deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, Octane renderer,lowres, bad anatomy, bad hands, text, missing fingers, worst quality, low quality, normal quality, signature, watermark, blurry,ugly, fat, obese, chubby, (((deformed))), [blurry], bad anatomy, disfigured, poorly drawn face, mutation, mutated, (extra_limb), (ugly), (poorly drawn hands), messy drawing,(2girls), morbid, mutilated, tranny, trans, trannsexual, [out of frame], (bad proportions), octane render, unity, unreal, maya, photorealistic
大概意思就是排除一些負面標籤,比如奇怪的手,奇怪的肢體,減少生成奇怪圖片的機率
Sampling Steps 你可以理解讓AI推演多少步,一般來說超過17基本就能看了,步數越多,畫面中的細節就越多,但需要的時間也就越久,一般20~30是一個比較穩妥的設定。這個數不會改變畫面內容,只會讓內容更加精細,比如20的項鍊就是一個心形鑽石,而50的項鍊還是同樣的心形鑽石,只是鑽石上會有更加複雜的線條
Sampling method 你可以理解成AI推演的演算法,一般Euler a,Euler ,DDIM,都是不錯的,任選一個就行。
圖片解析度 這個就是拼顯示卡視訊記憶體的,自己調吧,低於512X512可能畫面就不會有太多細節了,越大的解析度AI能發揮的地方就越多。
如果想放大圖片,可以去這個網站,可以實現AI放大功能
https://replicate.com/nightmareai/real-esrgan
下邊是3個擴充套件選項,一般不需要勾選。
Restore faces:勾選後可以生成更真實的臉,第一次勾選使用時,需要先下載幾個G的執行庫。
Tiling:讓圖片可以平鋪(類似瓷磚,生成的圖案左右上下都可以無縫銜接上自己)
Highres. fix:超解析度,讓AI用更高的解析度填充內容,但生成的最終尺寸還是你上邊設定的尺寸。
生成幾次,每次多少張
Batch count:是一次執行幾次
Batch size: 是同時生成多少張
比如:Batch count設定為4,用時N分鐘*4,生成4張圖;Batch count設定為4,用時N分鐘,生成4張圖,但是同時需要的視訊記憶體也是4倍。512X512大概需要3.75GB視訊記憶體,4倍就是15GB視訊記憶體了。
CFG Scale AI有多參考你的Prompt與Negative prompt
開得越高,AI越嚴格按照你的設定走,但也會有越少的創意
開的越低,AI就越放飛自我,隨心所欲的畫。
一般7左右就行。
Seed 隨機數種子,AI作畫從原理上其實就是用一個隨機的噪聲圖,反推回影像。但因為計算機裡也沒有真隨機嘛,所以實際上,AI作畫的起始噪聲,是可以量化為一個種子數的。
Generate 開始幹活按鈕,這個就不用說了吧,點了AI就開始幹活了。
Stable Diffusion checkpoint 在最左上角,是選擇模型的,前邊讓你下載了三個,請根據自己需求和體驗自行選擇使用。
後話
使用NovelAILeaks模型,有一個額外的設定,請在頁面中選擇【settings選項卡】,把頁面往下拉到底,找到Stop At last layers of CLIP model,把他設定為2
AI作圖不是釋放魔法,不是魔咒越長施法前搖越長的魔咒威力就越大。請簡潔、準確、詳細的描述你需要的Prompt即可。像我上邊的要求就是,1個蘿莉,穿白色連衣裙,瞳孔紅色,長髮,白色,帶髮卡,貓耳,微笑,陽光下。半透明材質衣服,已經WebUI是有75個詞限制的。
如果你想生成更大尺寸的圖,但是顯示卡視訊記憶體不足
用文字編輯器開啟\stable-diffusion-webui\webui-user.bat。
在COMMANDLINE_ARGS=後新增–medvram
如果還不行,改成–medvram –xformers
如果還不行,改成–medvram –opt-split-attention –xformers
如果還不行,改成–lowvram
如果還不行,改成–lowvram –xformers
如果還不行,改成–lowvram –opt-split-attention
注意這是個用生成時間換圖片尺寸的事情,最極端的引數可能導致你圖片生成時間是之前的好幾倍。
最極端引數是個什麼概念呢,比如預設配置512X512一張圖是10秒內,但視訊記憶體需要4G,改成最極端配置,視訊記憶體僅需0.5~0.7G(和Sampling method有關),但代價是時長變成3分鐘。
16XX系顯示卡,需要用文字編輯器開啟\stable-diffusion-webui\webui-user.bat。
在COMMANDLINE_ARGS=後新增–precision full –no-half
類似下邊這樣,不然生成圖會是黑塊或者綠塊,這是個16XX系顯示卡的bug
@echo off set PYTHON= set GIT= set VENV_DIR= set COMMANDLINE_ARGS=---precision full --no-half call webui.bat
示意圖中tag如下,理論上只要引數完全一致,就可以復現出一樣的畫(僅些微細節不同)
Stable Diffusion checkpoint:NovelAILeaks 4chan[925997e9] prompt: (((masterpiece))),((best quality)), flat chest,((loli)),((one girl)),very long hair,light white hair, red eyes,aqua eyes,white robe, cat ears,(flower hairpin),sunlight, light smile,beautiful detailed blue necklace,see-through, Negative prompt: ((part of the head)), ((((mutated hands and fingers)))), deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, Octane renderer,lowres, bad anatomy, bad hands, text, missing fingers, worst quality, low quality, normal quality, signature, watermark, blurry,ugly, fat, obese, chubby, (((deformed))), [blurry], bad anatomy, disfigured, poorly drawn face, mutation, mutated, (extra_limb), (ugly), (poorly drawn hands), messy drawing,(2girls), morbid, mutilated, tranny, trans, trannsexual, [out of frame], (bad proportions), octane render, unity, unreal, maya, photorealistic Steps: 27, S ampler: Euler a, CFG scale: 7, Seed: 2413789891, Size: 1024x768, Model hash: 925997e9, Clip skip: 2

![[3D][I社]愛語心通 / AiComi V1.07漢化整合免安裝版](/wp-includes/bb/timthumb.php?src=https://image.tiangal.com/2026/01/2026011817190863.webp&h=110&w=185&q=90&zc=1&ct=1)
![[AVG]玻璃青春 AI漢化版](/wp-includes/bb/timthumb.php?src=https://image.tiangal.com/2025/12/2025120803364344.webp&h=110&w=185&q=90&zc=1&ct=1)
![[AVG]心縛深淵:夢魘 Heartsworn Abyss: NighTmaRes v0.56 漢化版+DLC](/wp-includes/bb/timthumb.php?src=https://image.tiangal.com/2025/11/2025111614114660.webp&h=110&w=185&q=90&zc=1&ct=1)



